
A Detailed Guide on Wfuzz
Many tools now create an HTTP request and let users modify its contents. Similarly, fuzzing works by sending the same type of request multiple times to a server, changing a specific section each time. When users replace that section with a variable from a list or directory, they perform fuzzing.
In this article, we will learn how we can use wfuzz, which states for “Web Application Fuzzer”, which is an interesting open-source web fuzzing tool. Since its release, many people have gravitated towards wfuzz, particularly in the bug bounty scenario. So, let’s dive into this learning process.
Introduction to Wfuzz
Wfuzz provides a Python-coded solution to fuzz web applications with a wide array of options. Moreover, it offers various filters that allow you to replace a simple web request with a required word, substituting it with the variable “FUZZ.”
Setup
To install wfuzz using pip, we can:

Alternatively, users can achieve the same result by installing from source using Git.

The help menu to see all the working options is as follows:

You can use a module by using “-z”
Wfpayload and Wfencode
When you install the tool from the source, compiled executables called wfpayload and wfencode are available. These are responsible for payload generation and encoding. They can be individually used. For example, the command to generate digits from 0 to 15 is as follows:

As you can see, there is a pycurl error. It can go away like so:

Now, when you run wfencode, which is a module to encode a supplied input using a hash algorithm, there is no pycurl error now.

Docker run wfuzz
Users can also launch Wfuzz via Docker with the method below, using the ghcr.io repo. After replacing the last variable with wfuzz, they can run it without issues.

Payloads
In Wfuzz, a payload serves as the input source. To view available payloads, users can run:

For a more detailed view, they can apply the slice filter to the output.

Subdomain Fuzzing
Subdomain discovery plays a crucial role in pentesting scenarios. Often, attackers target subdomains instead of the main domain. Users can fuzz subdomains like this:
Here, -c color codes the output response codes
-Z specifies a URL to be input in scan mode and ignores any connection error
-w specifies the wordlist use while subdomain bruteforce.

The same can be achieved by providing the subdomain list inline too. Only, the payload (-z option) should be supplied in with “list” as an input. The list is supplied in the format ITEM1-ITEM2-ITEM3 like so:

Directory Fuzzing
You can enumerate directories using wfuzz, just like with gobuster, by employing a supplied wordlist. To do this, use the -w flag and input the path to the wordlist.

As you can see in the above screenshot, all the results, including “page not found,” have been dumped. This makes it tedious to go through the output and find a pin in a haystack. Therefore, to sort the results, we can use the –sc flag (show code). Other useful flags include:
- –hc/sc CODE #Hide/Show by code in response
- –hl/sl NUM #ide/Show by number of lines in response
- –hw/sw NUM #ide/Show by number of words in response
- –hc/sc NUM #ide/Show by number of chars in response

Saving fuzzing output
You can also save Wfuzz output in multiple formats by using the -f option.
-f option allows a user to input a file path and specify a printer (which formats the output) after a comma.

In place of csv, you can specify any one of the printers

Basic wordlist filters
There are certain sub-arguments that can be preceded by -z or -w filter to play around more with. These filters are:
–zP <params>: Arguments for the specified payload
–zD <default>: Default parameter for the specified payload
–zE <encoder>: Encoder for the specified payload
So, to specify a wordlist with the payload, we can do it like so:

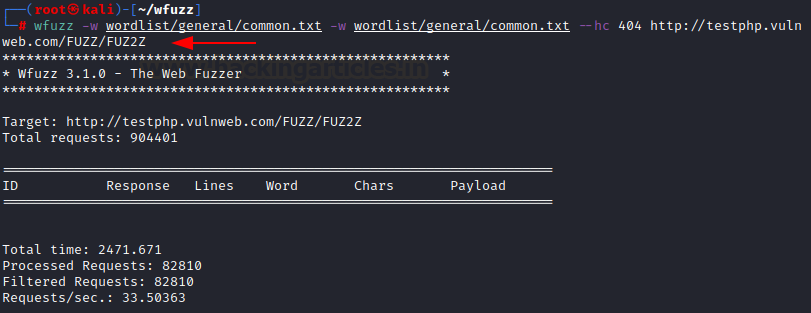
To hide the HTTP response code 404, the same can be obtained like so:

Double fuzzing
Just like a parameter in a payload can be fuzzed using the keyword “FUZZ”, multiple fuzzing is also possible by specifying multiple keywords.
- FUZ2Z – 2nd parameter
- FUZ3Z – 3rd parameter
- FUZ4Z – 4th parameter
And each parameter can be allotted its own wordlist. The first “-w” stands for first FUZZ. Second “-w” holds for the second FUZ2Z and so on.
Login bruteforce
HTTP responses can be brute-forced using wfuzz. For instance, testphp’s website makes a POST request to the backend, passing “uname” and “pass” as arguments to the userinfo.php page.

Similarly, you can implement the same attack using wfuzz like so:
The -d argument specifies the POST data to send along with the request:

As you can see, we found the correct credentials — “test-test.” We used a common file for both username and password. Alternatively, you can provide different files for each, like so:
Finally, the -c option color codes the output response, though you can skip it if preferred.

Cookie fuzzing
To send a custom cookie along a request to different fuzzed directories we can use the “-b” plug. This would add a cookie to the sent HTTP request.
Scenario useful:
- Cookie poisoning
- Session hijacking
- Privilege Escalation

In the above scenario, we have added 2 static cookies on multiple directories. Now, we can also fuzz the cookie parameter too like so:

Header fuzzing
HTTP header can be added in a request being sent out by wfuzz. HTTP headers can change the behaviour of an entire web page. Custom headers can be fuzzed or injected in an outgoing request
Scenarios useful:
- HTTP Header Injections
- SQL Injections
- Host Header Injections

HTTP OPTIONS fuzzing
There are various HTTP Request/Options methods available that can be specified by using the “-X” flag. In the following example, We have inserted the following options in a text file called options.txt
- GET
- HEAD
- POST
- PUT
- DELETE
- CONNECT
- OPTIONS
- TRACE
- PATCH

As you could see, three valid options returned a 200 response code.
The same can be input inline using the “list” payload like so:

Fuzzing through Proxy
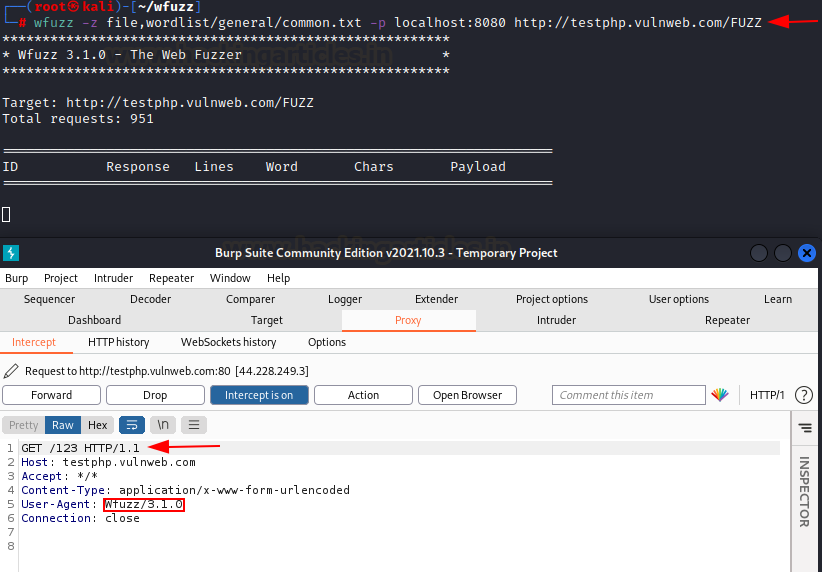
Wfuzz can also route the requests through a proxy. In the following example, a Burp proxy is active on port 8080 and the request intercepted in the burp intercept as you can see.
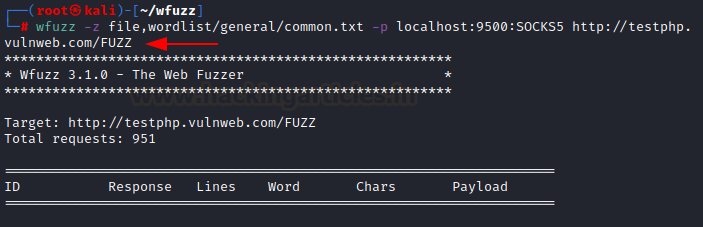
The same can also be achieved with SOCKS proxy like so:
Authentication fuzz
Wfuzz can also set authentication headers and provide means of authentication through HTTP requests.
Flags:
- –basic: provides basic Username and Password auth
- –ntlm: windows auth
- –digest: webserver negotiation through digest access
In the following example, I am providing a list inline with two variables and –basic input to bruteforce a website httpwatch.com

Recursive fuzz
-R switch can specify the levels of recursion while fuzzing directories or parameters. Recursion in simple terms means fuzzing at multiple different levels of directories like /dir/dir/dir etc
In the following example, we are recursing at level 1 with a list inline containing 3 directories: admin, CVS and cgi-bin. Note how a directory with – in its name can be supplied inline

Printers and output
Printers in wfuzz refers to all the formats a payload’s output can be processed as. It can be viewed using -e succeeded by printers argument. Furthermore, “-o” flag can specify the format of the output too

Encoders
Various encoders are available in wfuzz. One such encoder we saw earlier was md5. Other encoders can be viewed by using “-e” flag with encoders argument.

One can fuzz a website for directories by using MD5 output like so:

Storing and restoring fuzz from recipes
To make scanning easy, wfuzz can save and restore sessions using the “–dump-recipe” and “–recipe” flag.

Ignoring exceptions and errors
Often while fuzzing, there are various errors and exceptions that a website can throw. “-Z” option can make wfuzz ignore these errors and exceptions. First, we run a normal subdomain fuzzing routine and then with -Z option:
As you could see, -Z ignores that error on the bottom. Further, any invalid response can also be hidden like so:

Filtering results
There are many filters available to manipulate a payload or output.

These can be manipulated using “–filter, –slice, –field and –efield” arguments.
For example, to view raw responses of the payload sent and the complete HTTP request made, you can use “–efield r” option

However, if only the intended URL is needed, one can do it by providing –efield url input.

Similarly, to filter out results based on the response code and the length of the page (lines greater than 97), you can do it like:

A detailed table of all the filters for the payloads can be found here.
Sessions in wfuzz
A session in wfuzz is a temporary file which can be saved and later picked up, re-processed and post-processed. This is helpful in situations where one result saved already needs alterations or an analyst needs to look for something in the results. “–oF” filter can save the session output to a file.

This session file can now be opened up again and consumed using the “wfuzzp” payload like so:

One such example of this filteration from a previously saved session is as follows where we find an SQL injection vulnerability by utilizing a Python regex designed to read responses after a request modifies a parameter by adding an apostrophe (‘) and fuzzing again. “-A” displays a verbose output.
The regex r.params.get=+’\’ adds apostrophe (‘) in the get parameter. r stands for a raw response.

Conclusion
Wfuzz is a versatile tool that can perform more than just directory enumeration and truly help a pentester in his analyses. It’s a fast scanner that is easy to use and coded in python for portability. Hope you liked the article. Thanks for reading.
















 HACK RF RADIO AND NET HUNTER PHONE
HACK RF RADIO AND NET HUNTER PHONE



 USING WIGLE + WIFITE + ALFA ADAPTER
USING WIGLE + WIFITE + ALFA ADAPTER
 Daily practice and real-time application is key to perfection
Daily practice and real-time application is key to perfection